
【導讀】本文主要介紹MEMS麥克風陣列所需的硬件架構,利用MEMS麥克風陣列定位并識別音頻和語音信源。自從微機電系統的麥克風陣列的出世,麥克風音頻定位就引起各界關注。
目前業界正在使用MEMS麥克風陣列子系統開發嵌入式音頻定位、自動語音識別和自動說話人識別解決方案,聲音識別定位是我們識別確認他人身份的基本功能,當我們聽到有人講話時,會將頭轉向說話人,查看說話人。
音源定位是自動語音識別和自動說話人識別系統的一個重要環節,對于提高語音識別系統的性能至關重要。麥克風陣列可捕捉從不同方向傳來的聲音,通過算法運算使麥克風指向某一個特定方向,放大從該方向捕捉到的音頻信號,同時衰減從其它方向捕捉的音頻信號,整個動作就像一個智能麥克風。
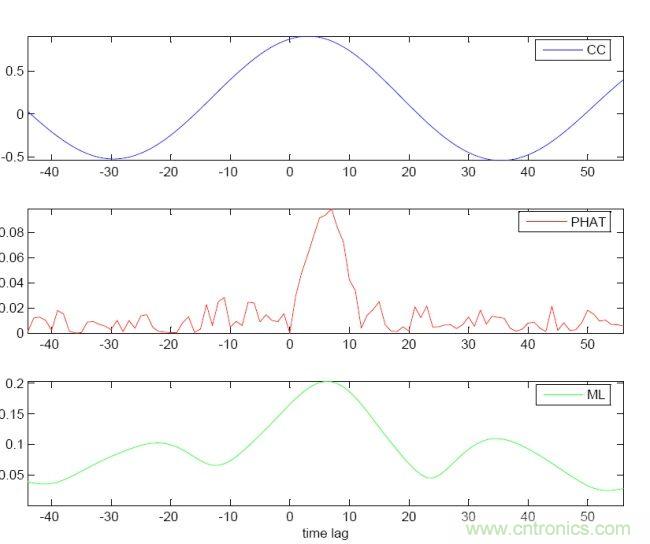
圖1:綜合利用麥克風音源互相關性(CC)、相變(PHAT)和最大相似性處理(ML)技術的音源定位
系統框架
整個系統由以下幾個子系統組成:音源方向測定、數據融合、自動語音識別和自動說話人確認。其中,音頻方向測定子系統基于麥克風陣列,運行三個不同的音頻方向估算算法;數據融合子系統負責推斷方向,自動語音識別子系統利用傳入的音頻信號增強主音源信號強度,衰減主音源周圍的其它音頻信號。最后,自動說話人確認子系統識別某些關鍵詞匯,再利用相關特征與說話人匹配。
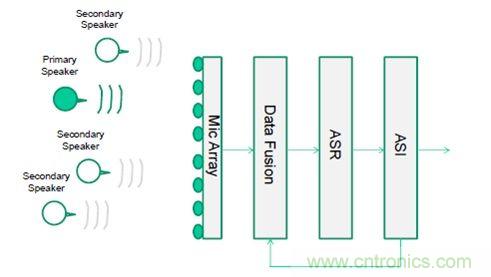
圖2.系統框架(注:Secondary speaker:副揚聲器;primary speaker:主揚聲器;mic array:麥克風陣列;data fusion:數據融合)
如果語音識別任務沒有成功,則反饋給數據融合系統,估算新方向傳入的語音,然后驅動麥克風陣列指向該方向。
[page]
語音識別和說話人識別
語音特征提取(27 LPC-倒普系數)需要確定語音的端點,將語音分成數個短禎(每禎20 ms),通過一個DTW模式對準算法與一組參考語音(模板)匹配。然后,應用歐氏距離測量法進行相似性評估。
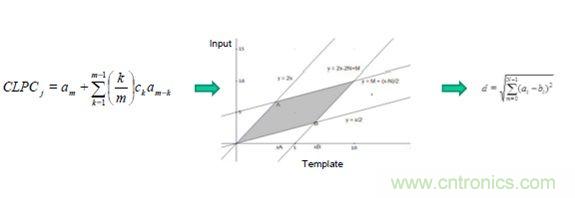
圖3. 特征提取、模式匹配和評分是說話人語音識別確認任務的主要環節
說話人身份評分采用的是動態時間規整近鄰(DTW-KNN)算法的距離測量方法,即動態時間規整測量算法與近鄰決策算法的合并算法。這個算法需要使用均方根、過零率、自動相關和倒普線性預測系數。使用歐氏距離算法計算成本函數,使用KNN 算法計算最小距離匹配度 k。
MEMS麥克風陣列
我們采用STM32F4微控制器和MEMS麥克風開發一個硬件音頻信號同步采集處理子系統,其信號捕捉能力相當于8個采樣率高達48 KHz的麥克風 。

圖4.采用STM32F4微控制器和MEMS麥克風的硬件音頻信號同步采集處理子系統
MEMS技術
MEMS技術的主要特性是在能夠同一芯片表面集成微電子和微機械單元,在同一封裝內整合不同的功能。這樣,過去分別由傳感器、執行器(例如,射流管理或機械交互)和邏輯、控制單元完成的不同功能,今天可以整合在同一個封裝內。從生化分析,到慣性系統,從機械傳感器,到音頻和聲波傳感器, MEMS產品覆蓋很多應用領域。
MEMS麥克風和音頻編碼
MEMS麥克風尺寸雖然比其它技術麥克風小,但是,從物理和機械角度看,卻具備標準駐極體麥克風的全部功能,其核心部件是一個振膜,振膜和固定框架共同組成一個可變電容器。當聲波引起振膜變形時,電容會發生變化,從而導致電壓變化。
被捕捉到的信號的后期處理,即功率放大和模數轉換過程,都是在同一芯片上完成,因此,麥克風輸出是高頻PDM信號。在脈沖密度調制過程,邏輯1對應一個正 (+A)脈沖,而邏輯0對應一個負(-A)脈沖。因此,假設輸入一個周期的正弦音頻,當輸入電壓在最大正振幅時,輸出為一個由“1”組成的脈沖序列;當輸入電壓在最大負振幅時,輸出則是一個由“0”組成的序列。當穿過0振幅時,聲波在1和0序列之間快速變化。如果方法正確,PDM可通過數字方法給高品質音頻編碼,而且實現方法簡易,成本低廉。因此,PDM比特流是MEMS麥克風常用的數據輸出格式。
另一方面,PCM是一個非常著名的音頻編碼標準,以相同的間隔對信號振幅定期采樣,在數字步進范圍內,每個采樣被量化至最接近值。決定比特流是否忠實原模擬信號的是PCM比特流的兩個基本屬性:采樣率,即每秒采樣次數;位寬,即每個采樣包含的二進制數個數;通過降低采樣率(降低十分之一)和提高字長,可以將PDM編碼信號轉成PCM信號,PDM數據速率與降低十分之一的PCM采樣率的比值被稱為降采樣率。因此,對于N:1降采樣率,只要每N個間隔采樣一次(不考慮剩余的N-1),即可完成降低十分之一的采樣過程。
麥克風陣列
從硬件角度看,這款產品基于STM32F407VGT6高性能微控制器,能夠通過8個MEMS麥克風采集信號。STM32F4微控制器基于工作頻率最高168 MHz的高性能ARM Cortex-M4 32 RISC處理器內核,集成高速嵌入式存儲器(閃存容量最高1 MB, SRAM容量最高192KB)以及標準和先進的通信接口,例如,I2S全雙工接口、SPI、 USB FS/HS和以太網。
麥克風陣列通過RJ45以太風接口或USB OTG FS接口連接其它器件,與其它器件交互是通過可控制基本板設置的DIP開關實現。
如下圖所示,每個MEMS麥克風都是由同一個時鐘源觸發,時鐘源由專用振蕩器驅動,對每個GPIO端口的一個引腳輸出1位PDM 高頻信號。輸出PDM數據頻率與輸入時鐘同步,因此,DMA控制器以同一頻率即音頻捕捉頻率對GPIO端口進行讀操作,然后將1 ms音頻數據(每次)保存在存儲器緩沖電路。這時,該緩沖器包含麥克風交叉信號,然后軟件利用優化的快速解碼函數對數據進行解復用處理。最后,PDM 數據通過數字信號處理環節,再進行PDM轉PCM處理。
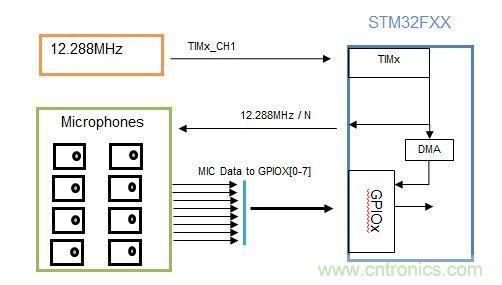
圖5.每個MEMS麥克風都是由同一個時鐘源觸發,時鐘源由專用振蕩器驅動,對每個GPIO端口的一個引腳輸出1位PDM高頻信號
麥克風傳來的PDM信號經過過濾和十分之一降采樣率處理,以取得所需頻率和分辨率的信號。麥克風輸出的PDM數據頻率(麥克風的輸入時鐘)必須是系統最終音頻輸出的倍數,濾波器管道輸出是一個16位值,我們將 [-32768, 32767]視為一個單位增益(0 dB)的輸出范圍。
原先濾波管道產生的數字音頻信號在信號調理前被進一步處理。管道第一級是一個高通濾波器,主要用于除掉信號DC失調。為保護信號質量,該濾波級是使用一個截止頻率不在可聽頻率范圍內的 IIR濾波器,管道第二級是一個基于IIR濾波器的低通濾波器。兩個濾波器有啟用和禁用以及配置功能;可通過外部整數變量控制增益。

圖6.麥克風傳來的 PDM信號經過過濾和十分之一降采樣率處理,以取得所需頻率和分辨率的信號
如上文所述,數據采集有兩個比特流解決方案,通過DP開關選擇用哪一個方案。當選用 USB且在主機USB插入麥克風陣列時,主機將STM32_MEMS_Microphones視為一個標準的USB音頻設備。因此,主機系統無需安裝驅動軟件。例如, STM32_MEMS_Microphones可直接連接第三方PC音頻采集軟件。當選用以太網時,STM32_MEMS_Microphones發送RTP數據包。在網絡服務器的以太網設置頁對目的地IP、設備單播地址和采集參數進行配置。
結語
音源定位識別是語音識別技術中的一個重要的語音預處理環節,對提高音頻應用和聲控應用性能具有重要意義。音源定位主要用于自動語音識別、音頻模式識別、說話人發現及識別。MEMS技術的問世讓麥克風陣列能夠嵌入在上述應用設計中,執行音頻信號預處理過程,為應用級提供最好的信息。
該嵌入式單個說話人及其語音定位識別方案基于一個集成ARM處理器和一組MEMS麥克風的原型板。初步測試結果證明了這一集成方案的可行性,且系統級模塊可以做語音、音頻識別目標板,滿足人機、人與周圍環境的自然用戶界面的功能要求。
相關閱讀:
通透了解MEMS硅晶振,只需一篇文章即可
MEMS慣性傳感器在工業控制的未來之路
技術圖解MEMS壓力傳感器的原理與應用


